토스의 인프라 모니터링
Table of contents
이 포스트는 토스ㅣSLASH 21 - 토스의 서버 인프라 모니터링 유튜브 영상을 참고하여 본인의 의견이 첨가된 내용으로 포스팅을 재구성한 글임을 미리 밝혀 둡니다. 만약 토스 관계자분께서 해당 포스팅의 게재를 원치 않으시거나 수정이 필요하다고 판단되면 이메일로 연락 부탁드립니다.
본 내용은 kubernetes, Istio, 프로메테우스 에 대한 지식이 없다면 이해하기 힘들 수 있습니다. 본 포스팅에서 해당 개념을 따로 설명을 드리지 않습니다.
개요
토스의 서버 인프라는 2019년에 대대적인 변화가 있었는데, 그 당시 컨테이너 기반의 오케스트레이션 시스템으로 vamp, DC/OS 기반의 인프라를 사용하였다. DC/OS는 컨테이너 오케스트레이션 엔진이고, vamp는 마이크로 서비스에서 서비스 디스커버리를 담당하는 API Gateway 컴포넌트이다. 하지만 운영 한계를 느껴 엔진을 변경하게 되었다고 소개하고 있다.
이후 kubernetes, Istio 기반으로 마이그레이션 하게 되는데, kubernetes는 잘 아시다시피 컨테이너 오케스트레이션이고 Istio는 쿠버네티스 클러스터에서 컨테이너의 연결, 모니터 및 보안을 구성하는 메시 서비스이다. 설명이 조금 어려운데 쉽게 설명하면 쿠버네티스에 있는 pod,svc 같은 컴포넌트들이 네트워크 통신이 원할하게 진행하고 있는지 시각화된 도구로 모니터링 할 수 있는 도구라고 할 수 있습니다. 원리는, 실제 내부에 프록시 서버를 두어 경유하게 함으로써 수집된 데이터를 DB에 적재하여 화면에 보여주는 역할입니다.
엔진의 변화 외에도 모니터링 시스템에도 변화가 있었는데, 기존에는 influxdb, telegraf 으로 모니터링을 진행했다고 한다. 그러나 엔진을 쿠버네티스로 변경하면서 좀더 친화적인 prometheus, thanos 으로 변경하게 된다.
오류가 발생했을때 로그를 보고 문제 원인을 발견할 때도 있으나 로직이 복잡하거나 트랜잭션이 길 경우 파악이 잘 안된다. 보통 잘 동작하다가 갑자기 오류가 나는 이슈가 까다롭고 자주 겪게 된다. 이때 메트릭이 원인 규명에 도움이 된다. 소스코드 상의 오류가 아닌 외적인 요소의 오류(메모리, CPU 같은 자원 부족 및 네트워크상 오류 등)로 발생한 경우도 많이 있다.
메트릭 레이어 3단계
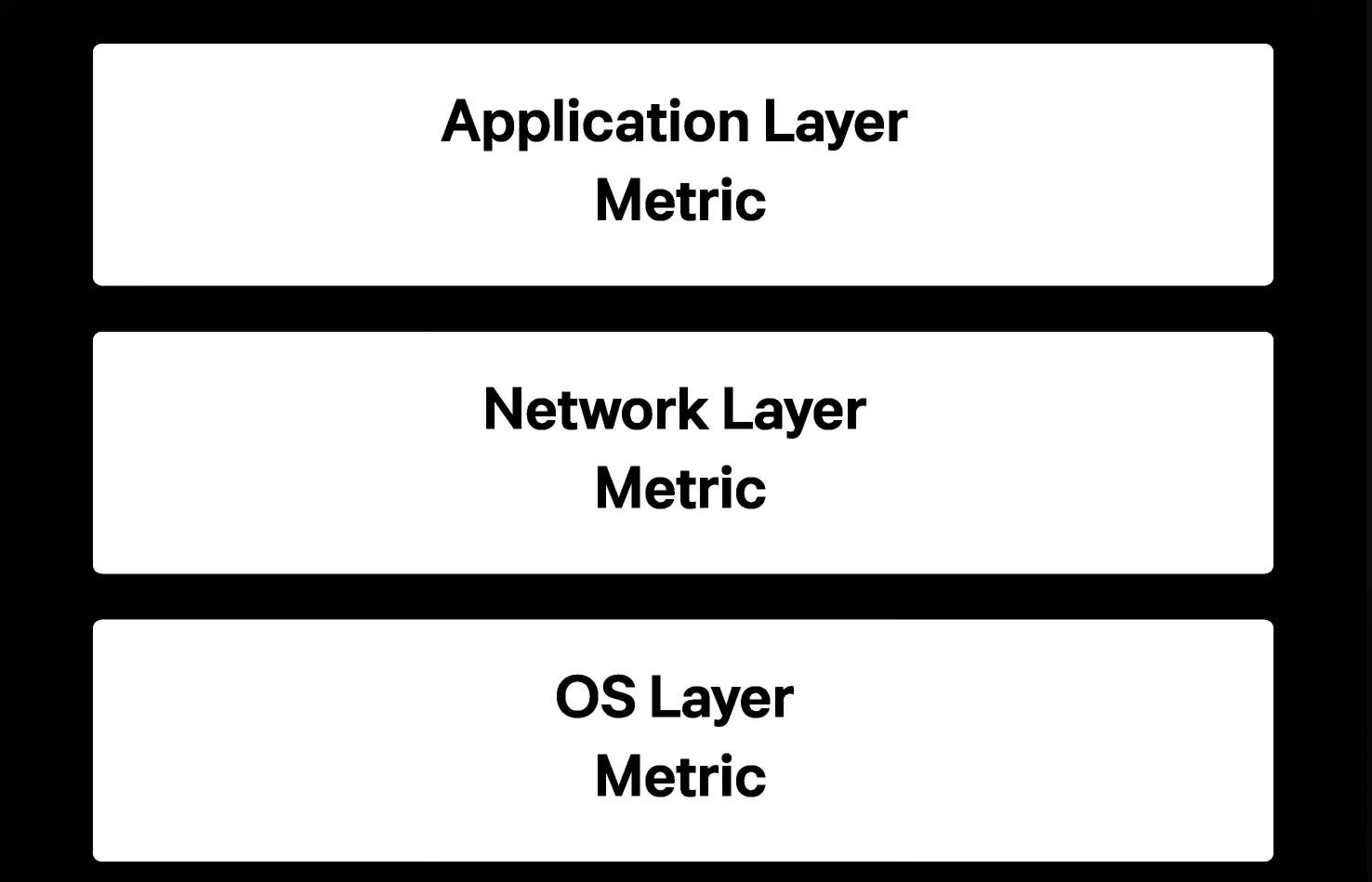
-
Application Layer Metric : 첫번째는 어플리케이션 레이어 이다. 토스의 경우 스프링 프레임워크가 대다수여서 JVM 메트릭이나 톰켓 메트릭, JPA 메트릭을 계속 모니터링 했다고 밝히고 있다. 로깅과 가장 상관관계가 높은 단계의 메트릭이기 때문에 이 레이어부터 확인하게 된다. 여기서 특이한 현상이 없으면 네트워크를 관찰하게 된다.
-
Network Layer Metric : 두번째는 네트워크 레이어 이다.서비스간의 통신이 원할한지 확인 한다. 극단적인 케이스에선 요청 자체가 ingress 로 들어오지 못해 큰 장애가 날 수 있기 때문에 모든 네트워크 퍼널이 정상적인지 알려줄 가시성도 확보해야 한다.
-
OS Layer Metric : 세번째로는 OS 레아어 이다. 서버의 리소스가 얼마나 잘 분배되거나 부족한건지 그리고 에러가 발생하는지 판단할 수 있도록 하는 지표이다. 해당 지표는 로깅과 트레이싱을 확인해 봤을 때 가장 상관관계가 낮기 때문에 마지막에 판단할 근거를 제시하게 해 준다.
영상의 주 목적은 인프라 단계의 모니터링이기 때문에 Network Layer 와 OS Layer 에서 발생한 문제를 주로 어떻게 문제를 발견하고 해결 했는지 소개하고 있다.
Network Layer Metric
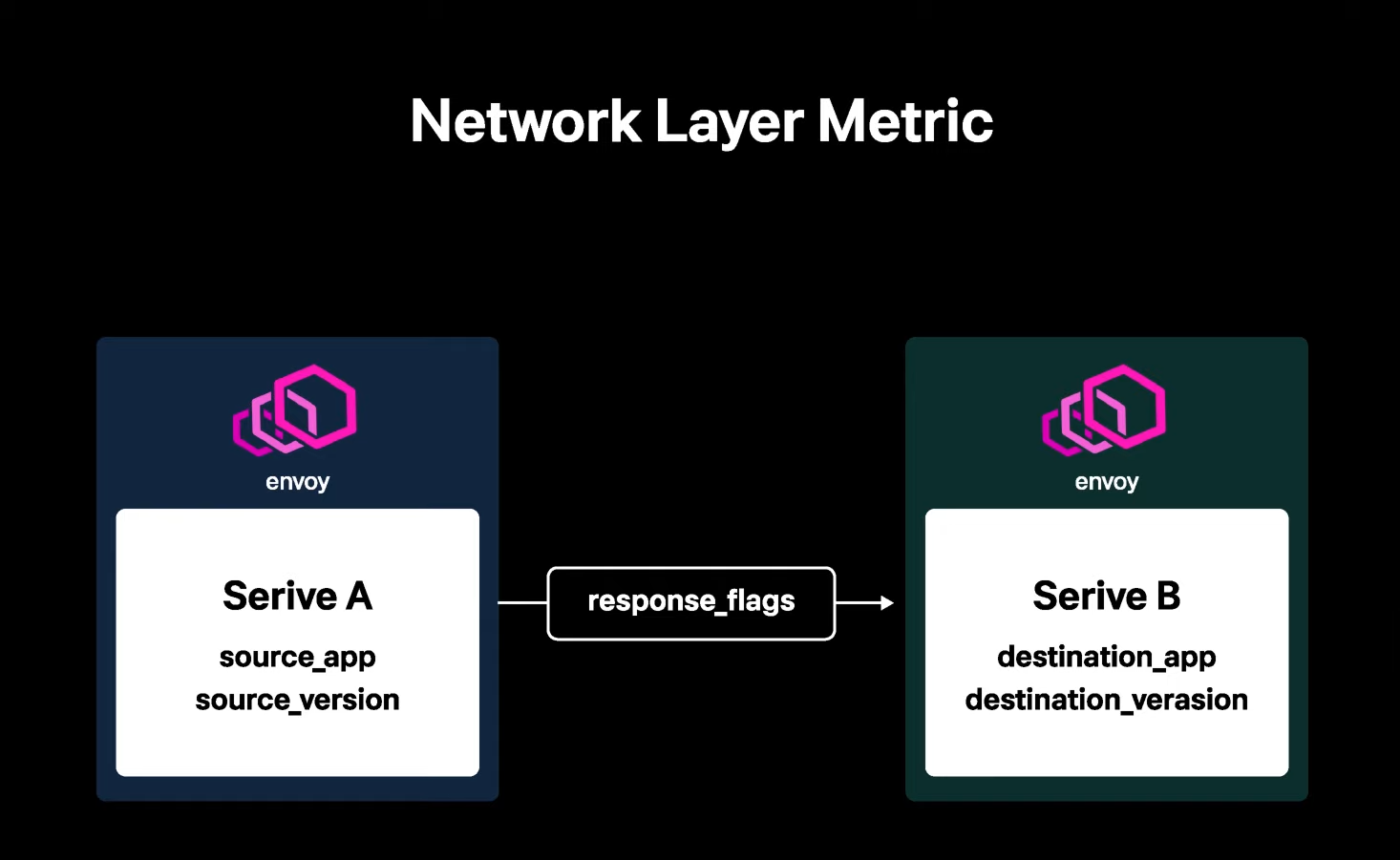
서비스 메쉬로 인프라가 변경되면서 네트워크 레이어에서 A 서비스가 B 서비스에게 어떤 요청을 넣었는지 알수 있게 되었다고 설명하고 있다. envoy 란 Istio 의 프록시 서버를 의미하는데, Istio를 사용해본 경험이 있다면 특별한 내용은 아닐 것이다. 내용을 요약하자면 Istio 를 사용하여 쿠버네티스 서비스간에 요청과 응답 네트워크를 한눈에 파악할 수 있었다는 내용이다.
추가적으로 response_flags 라는 지표를 활용할수 있게 되었는데, 하나의 요청 flow 에서 upstream, downstream 사이에서 어떤 비정상적인 현상이 있었는지 파악하는데 도움이 되었다고 설명하고 있다.


이후 Istio를 사용하면서 발생되는 요청 커넥션 이슈에 대해 설명하고 있다.
요약하자면, Istio를 도입함으로써 네트워크단에서 발생되는 이슈들을 잡는데 상당한 도움이 되었다고 설명하고 있다. 확실히 해당 부분은 애플리케이션까지 도달하지 못하므로 오류로 그를 발생하지 않을 테니 Istio 같은 서비스 메시가 있어야 해당 문제를 좀 더 빨리 파악을 할 수 있는 것 같다.

여기서 재미있는 설명이 나오는데, 토스의 쿠버네티스 환경구성 포스팅에서 언급했다시피 토스는 쿠버네티스 클러스터를 이중화로 구현하고 있었기에 위 사진 처럼 주기적으로 헬스 체크를 하여 문제가 발생시 다른쪽으로 라우팅을 돌려준다고 한다.
여기서 궁금했던점은, 두개의 클러스터는 서로 격리되어 운용되고 있을 터인데 클러스터 내부에서 특정 장애 발생시 다른 클러스터로 트래픽 보내는 방법에 대한 구체적인 방법에 대한 설명이 없어서 아쉬웠다.
위 사진에 나와있는 L7 스위치가 정확하게 어떤 서비스를 의미하는것인지 잘 이해가 되지 않았다.
Istio 라고 한다면 쿠버네티스 클러스터 내에 설치되어 있을 터인데, 클러스터 내부에서 다른 클러스터 내부로 접근이 가능한지? 그리고 그렇게 하는게 보안상 맞는건지 의문이 들었다. 클러스터 내부에 접근 하기 전 스위치 하는건 물리적으로 금방 이해가 되는데 이비 내부안으로 들어 온 상태에서 다른 클러스터 내부로 트래픽을 라우팅 하는게 맞는건가? 싶었다.
OS Layer Metric
기본적으로 OS도 상당히 복잡한 소프트웨어이다.
cpu, memory, network, disk, 커널 등 메트릭의 종류가 너무 많고 하드웨어 입장에서의 메트릭이라 서비스에서 발생하는 어플리케이션 오류와 상관관계를 찾기가 매우 힘들다. 가령 CPU 사용이 높다고 해서 어플리케이션이 제대로 동작하지 못했는지 답을 확실히 찾기 어려웠다.
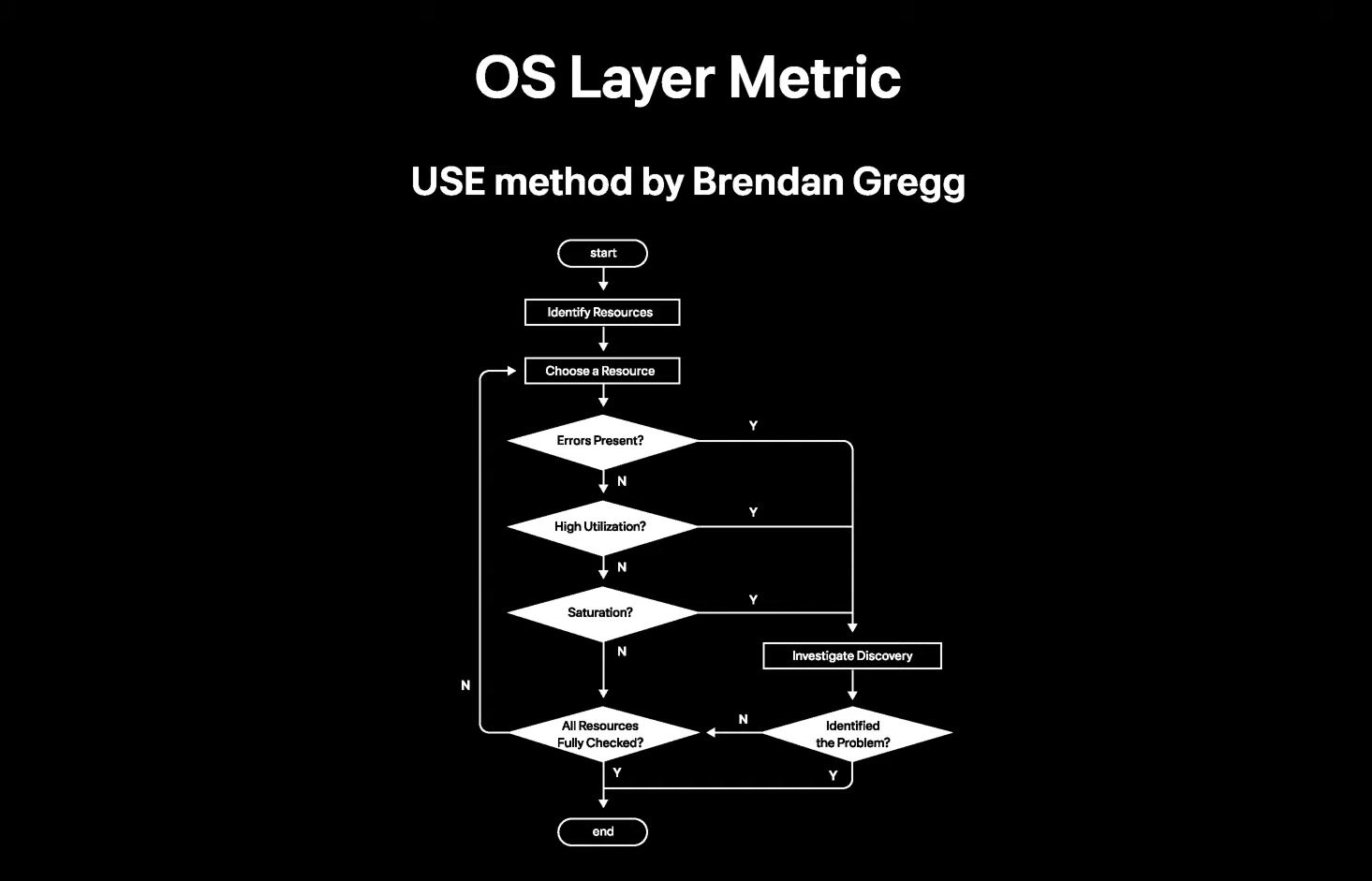
그러던 와중 USE method 가 좋은 인사이트를 주었다고 소개하고 있다. 문제가 발생했을 시 어떤 순서대로 문제를 파악하는게 좋은지에 대한 순서도 이다.
CPU

CPU의 경우 컨테이너의 CPU usage 를 알 수 있고, 컨테이너에서 리눅스 CPU 알고리즘인 cfs 쓰로틀량을 측정할 수 있어 이를 통해 얼만큼 포화상태인지 확인할 수 있어 CPU 가 문제 원인에 기여했다고 판단 한다고 한다.
Memory

메모리의 경우 컨테이너 입장에서 메모리를 쓰고 있는지 판단하고 추가적으로 어플리케이션이 메모리 영역을 나눠 관리한다면 그 메트릭으로 사용량을 판단한다. 하지만 얼마나 허용량에 다 이르었는지 판단하기에는 아직 직관적인 메트릭을 찾지 못했다고 밝히고 있다. 그래서 oom 이벤트로 포화상태를 판단했다고 한다.
oom 이란, out of memory 로 자바에서 메모리 부족시 해당 exception 이 발생하게 된다.
요악하자면, 결국 out of exception 이 발생하지 않았다면 메모리 이슈를 배제 했다고 밝히고 있다. 아마 메모리 모니터링은 실제로 오류가 발생하지 않는한 사전에 모니터링 하기에는 좋은 방법이 따로 없는가 보다.
disk

disk device 는 각 어플리케이션이 얼마나 read/write를 많이 하는지 OS 입장에서 disk total utilization 을 보고 io time이 얼마나 길어졌는지 보면서 포화된 양의 척도로 삼았다고 한다. 최종적으로는 error 여부를 보면서 이슈가 났을 때 이 원인이 disk 임을 판단할 수 있는 근거가 되었다.
그러나 서버 인프라에서는 보통 디스크에 저장하는게 없는데, 왜 사용량이 높은가 원인을 찾았다고 한다.
그것은 각 어플리케이션이 얼맘나 패킷을 받고 보내고 있는지 OS 입장에서 network total utilization 을 보고 사용량이 얼마큼인지 판단하고 ethtool을 통해 얼마나 drop 이나 overrun 이 되었는지 알수 있다고 한다.
해당 부분의 포화상태 측정은 컨테이너 네트워크에는 잘 잡히지 않기 때문에 해당 어플리케이션이 떠 있는 호스트 OS 입장에서 포화상태를 판단해 네트워크 디바이스에 이상이 없는지 보았다고 한다.
보통은 특정 어플리케이션이 트래픽을 과도하게 사용함으로써 동일한 노드에 있는 다른 어플리케이션이 제대로 통신하지 못하는 경우가 많다라는 것이고 이를 근거로 해당 어플리케이션의 네트워크 사용을 제한하는 과정을 거쳤다고 한다.
특정 어플리케이션이 과도하게 트래픽을 혼자 독식하고 있다면 다른 컨테이너는 정확한 오류를 알지 못한채 통신이 불가능하기 때문에 제한을 한 것으로 파악된다. 해당 부분은 꽤 많은 도움이 되었다. 막연하게 그냥 열어두면 알아서 통신하겠지 라고 생각했는데, 역시나 트래픽이 몰리는걸 그대로 손쓰지 않는다면 적절한 트래픽 분배가 안되고 먹통이 될 수 있기 때문인듯 하다.
근데 제한은 어떤식으로 하는거지? 쿠버네티스에 컨테이너 네트워크 제한을 하는 부분이 있었나 확인해 보아야 겠다.
프로메테우스 모니터링은 OS Layer 에서 발생하는 메트릭을 모니터링 하는 도구이다. 위에서 언급한 OS Layer 의 메트릭을 모니터링 하는 용도로 사용하고 있다.
장비의 문제
IDC 에서 서버를 운영하다보면 하드웨어 문제가 발생할 수 있다. 이때 서비스 디스커버리에서 해당 인스턴스에 있는 어플리케이션의 타겟을 제거해야 트래픽이 문제가 있는 장비로 흐르지 않게 된다. 과거에 자주 발생한 이슈라고 소개하고 있다.
AWS 같은 클라우드 서비스를 쓰면 해당 부분은 손이 좀 덜 가지 않을까? 해당 내용으로 비추어 보아 토스는 모든 서비스를 클라우드에 적극적으로 쓰고 있는게 아니라, 부분적으로 IDC 와 함께 사용하는것 같다.
이 장비의 문제를 해결한 방법이 생각외로 단순했는데, 1초마다 ping 을 날려 확인 했다고 한다.
모니터링 인프라에서 문제 발생
서버 인프라 뿐만 아니라 모니터링 인프라에서도 문제가 발생할 수 있다. 프로메테우스가 설치된 어플리케이션에서도 문제가 발생할 수 있다. 그래서 프로메테우스 서버가 내려가면 메트릭을 전혀 볼수 없는 신세가 되었다고 한다.
프로메테우스의 단점은 스스로 어플리케이션의 메트릭을 스크랩 하는 방식이다보니 프로메테우스를 동작하는 노드가 죽어버리면 메트릭 수집이 중단되어 중단된 만큼 메트릭이 누락될 수 밖에 없다.
두번째 단점으로는 메모리 이슈가 많았는데, 프로메테우스가 out of memory가 발생해 내려가고 그 시간동안은 메트릭을 볼 수 없었다.
당연하게도 해결책은 최대한 프로메테우스가 죽지 않도록 프로메테우스의 메모리 이슈를 해결해 나가는 것이다. 그래서 다음과 같은 해결 방법을 알려 주었는데
- 수집하는 메트릭 량을 줄이자
- 프로메테우스가 쌓고 있는 tsdb 의 사이즈를 줄이자
이 2가지를 고민했다고 한다. 과연 우리가 수집했던 모든 데이터를 보는지, 그리고 보는 메트릭의 카디널리티가 적합한지 판단했다고 한다. 그래서 케트릭 쿼리 카운트를 통해 어느 메트릭이 정말 많이 쌓이는지 보고 필요 없는 메트릭은 없애고 카디널리티가 너무 넓은 메트릭은 어그리게이션으로 축소해서 메트릭 양을 줄였다고 한다.
하지만 초반에는 어느정도 효과를 보았지만 결국 한계를 도달했다고 한다. 유지해야 하는 가시성이 있었기에 더이상 줄이지 못했다고 한다.
프로메테우스 문제 해결 방안
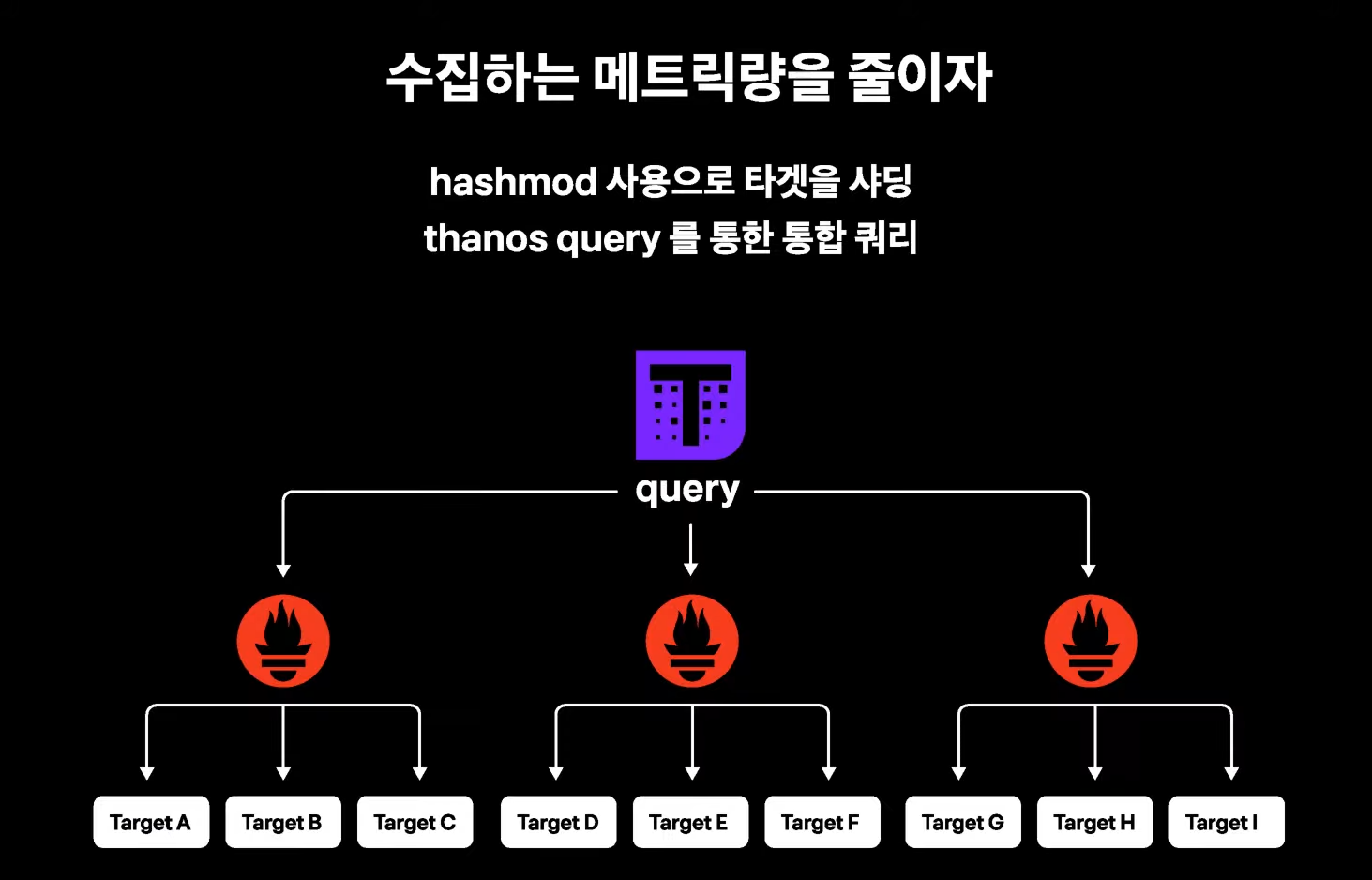
위에 언급한 것처럼 더이상 메트릭의 양을 줄일수 없는데도 계속해서 부하가 늘어났고 결국에 토스에서 선택한 것은 메트릭을 스케일 아웃했다고 밝히고 있다.
프로메테우스의 개수를 여러개로 늘려서 각 프로메테우스가 수집하는 메트릭 량을 줄이는 것이다. 다행이도 프로메테우스는 hashmod 라는 옵션으로 샤딩 기능을 제공해 준다고 한다.
프로메테우스를 샤딩까지 해서 사용해야 할 정도로 서비스 규모가 방대하다는 의미니 대단한것 같다.
프로메테우스 타노드 사이드카
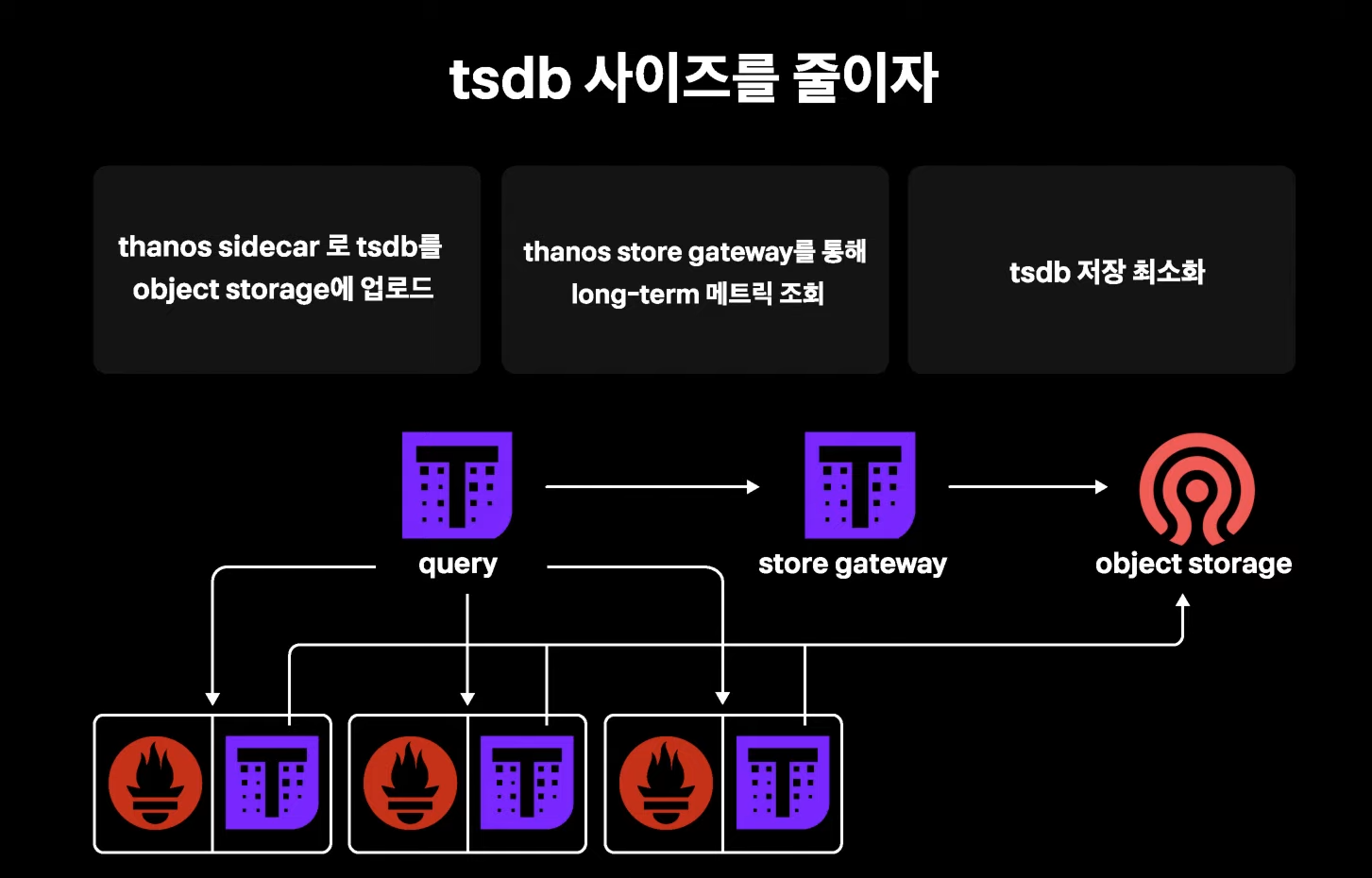
결국 프로메테우스는 tsdb 의 해결이 핵심인데, 프로메테우스에 타노스 쿼리를 붙여 tsdb를 object stoage 에 업로드할 수 있다고 한다. 이를 통해 스토어 게이트 웨이로 저장된 메트릭을 조회할 수 있다고 한다.
프로메테우스에는 tsdb를 저장을 최소화 하며 메트릭의 보관 기간도 기존보다 길게 가져갈 수 있어 프로메테우스 운영이 간편해 졌다고 한다.